From Requirement to Release: What Really Happens Inside Software Engineering
Understanding the structured process that transforms requirements into reliable software.
Sandeep Varma

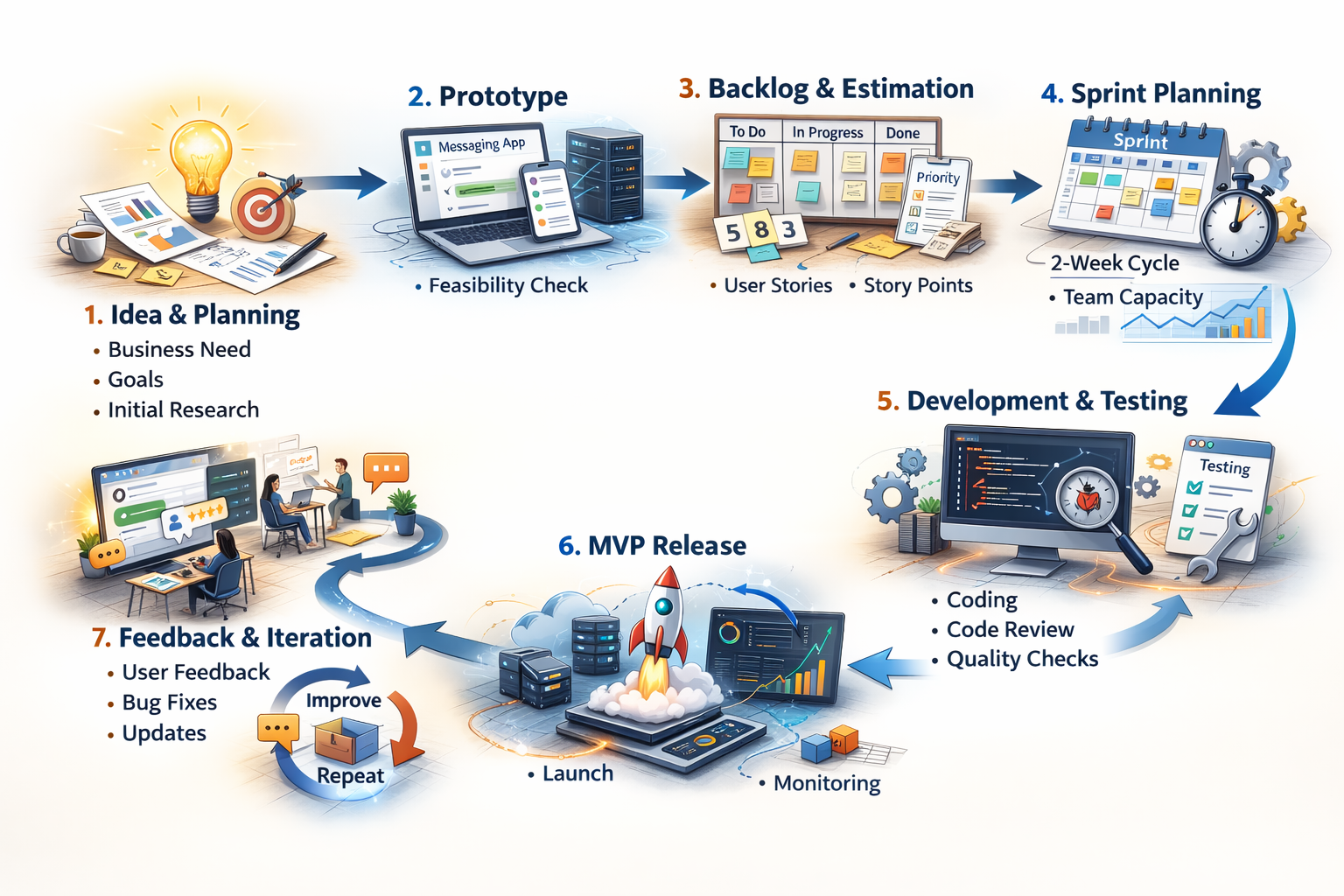
In a previous post, From Idea to Launch: How Software Actually Gets Built, we explored how software moves from idea to launch. We discussed business evaluation, product definition, refinement, estimation, sprint planning, and how work gets committed into a sprint.
In this post, we zoom into a much more detailed moment in that journey. What actually happens after a story has been prioritized and assigned to a software engineer?
This is the part of the lifecycle that many cross functional partners do not fully see. Yet it is where quality, discipline, and engineering rigor truly shape the final product.
Step 1: Understanding the Story and Acceptance Criteria
By the time a story reaches an engineer, it has already gone through refinement. It contains context, technical notes, and clearly defined acceptance criteria.
Acceptance criteria define what must be true for the story to be considered complete. They represent the definition of done from the perspective of the stakeholder, whether that is a product owner or an engineering manager.
For example, if the story involves building a direct messaging feature, the acceptance criteria might include that a user can send a message and see it appear instantly, that messages persist after a page refresh, and that only authenticated users can access the conversation. These criteria create a measurable target. Without them, engineers would be guessing.
Before writing any code, the engineer carefully reviews the story and ensures they fully understand what success looks like.
Step 2: Clarifying Questions and Technical Alignment
Even after refinement, questions may remain. As engineers unpack the story in detail, they may identify edge cases, technical constraints, or ambiguous wording.
At this stage, they ask clarifying questions to senior engineers, architects, or the product owner. This prevents incorrect assumptions and reduces rework later. Alignment early in the process saves significant time downstream.
Only once the scope is clear does the engineer begin implementation.
Step 3: Writing Code and Automated Tests
Modern software engineering does not separate development and testing as completely independent activities. As engineers write code, they also write automated test cases.
These tests can take different forms such as unit tests, integration tests, or component level tests. Each type serves a different purpose depending on the scope and complexity of the story. A deeper discussion on testing strategies deserves its own engineering focused post, but what matters here is that testing is embedded into development itself.
The goal is simple. The code should not only work today, but continue working tomorrow even as the system evolves. Automated tests provide that safety net.
Step 4: Local Testing and Development Environment Validation
After implementing the solution, the engineer first validates everything locally on their own machine. They confirm that the functionality behaves according to the acceptance criteria and that automated tests pass successfully.
Once satisfied locally, the changes are pushed to a development environment. The development environment is not public. It is typically accessible only to developers and sometimes to product partners who want early visibility.
In this environment, the engineer again verifies that the feature works in a setting closer to the real system configuration. At this point, the engineer takes ownership of validating their own work thoroughly before asking others to review it.
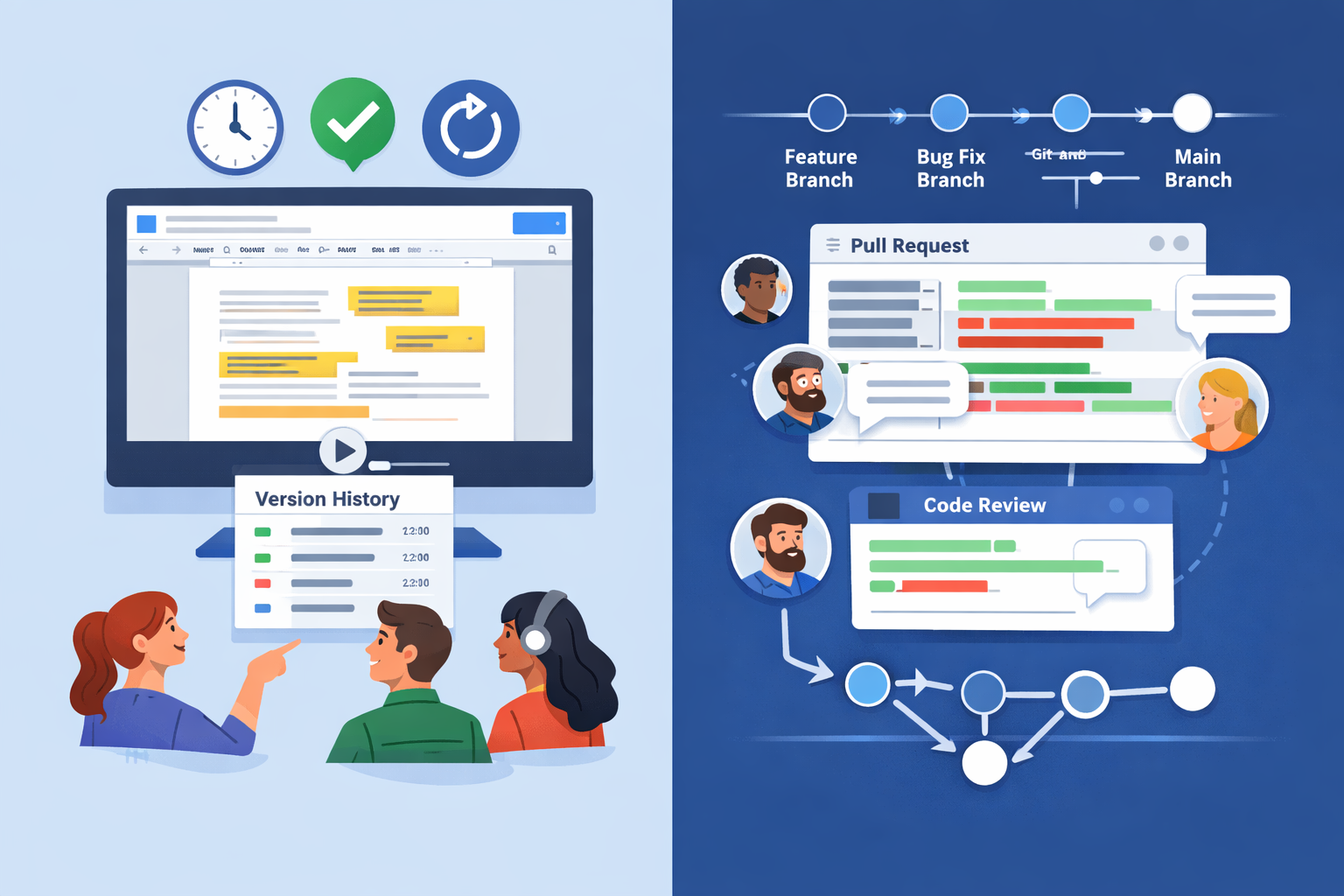
Step 5: Opening a Pull Request
When the engineer is confident in the implementation, they open a pull request, commonly referred to as a PR. This is done in a version control tool such as GitHub or GitLab, where the codebase is centrally managed.
A pull request shows exactly what changed. It highlights the difference between the previous version of the files and the new modifications introduced by the engineer. This structured comparison makes it easier for others to review the changes.
Engineers typically notify the team through collaboration tools so reviewers know a PR is ready. The review process begins. If you are unfamiliar with what pull requests are or how version control enables this collaboration, Understanding Git and Version Control for Non-Engineers provides a clear foundation.
Step 6: Peer Review and Approval
Peer review is one of the most important quality control steps in modern engineering.
Other engineers examine the code for clarity, correctness, performance considerations, and adherence to standards. If something looks unclear or potentially problematic, they leave comments requesting clarification or changes.
A back and forth discussion often follows. The original engineer may adjust the code or explain their reasoning. This collaboration improves both the code quality and shared understanding within the team.
Once reviewers are satisfied, they approve the pull request. Many teams require at least two approvals before changes can be merged. After approval, the code is merged into the main branch, which represents the official version of the software.
Step 7: CI/CD Pipeline and QA Environment
After the merge, an automated pipeline is triggered. A pipeline is a sequence of automated steps that build, test, and promote the application across environments. Some stages may require manual approval before proceeding.
The first stages often re run automated tests to ensure nothing breaks at integration level. If everything passes, the changes move to a QA environment.
The QA environment is closer to production in configuration, but it is still not public. Quality assurance testing happens here. While automated tests continue to run, certain scenarios may still require manual validation. Product owners, engineers, or engineering managers may test specific workflows to ensure business expectations are met.
If issues are discovered, the process loops back. Fixes are made, reviewed, and re promoted through the pipeline. On a related notes, understanding how Dev, QA, and Production environments differ from each other and why code must travel through each one is covered in Before Software Goes Live: Understanding Dev, QA, and Production Environments._
Step 8: Production Deployment and Release
Once QA validation is complete, a designated stakeholder approves promotion to production. Production is the live environment where real users interact with the system.
Modern deployment strategies allow teams to release changes with minimal or no downtime. Techniques such as blue green deployment enable a new version of the software to run alongside the old version. Traffic can gradually shift from the old version to the new one.
If something unexpected occurs in production, teams can quickly roll back to the previous stable version. This reduces customer impact and provides time to investigate the issue safely.
Deployment is not the end of the story. It is the beginning of real world validation.
Monitoring and Continuous Feedback
After release, teams monitor system performance, error rates, and user behavior. Observability tools provide insights into how the feature behaves under real traffic.
If issues surface, the team investigates, fixes the problem, and the cycle repeats. The same disciplined process applies again from development to review to deployment.
This loop of build, validate, release, monitor, and improve is the foundation of modern software engineering.
Closing Thoughts
When a story is assigned to an engineer, it enters a structured lifecycle designed to ensure quality, collaboration, and reliability. What may look simple on the surface involves multiple layers of validation, review, and controlled release.
Understanding this process helps cross functional teams collaborate more effectively. It clarifies why timelines require discipline, why reviews cannot be skipped, and why releases are carefully managed rather than rushed.
If you work closely with engineering teams, which part of this lifecycle has been the most opaque to you? Reflect on where communication feels strong and where misalignment tends to occur. That awareness alone can significantly improve how teams build software together.
Did you find this useful?
Comments
Loading comments...
Please log in to post a comment.
About the author

I write about leadership and software engineering through the lens of someone who’s worked as a software engineer, product owner, and engineering manager. With a Bachelor’s in Computer Science Engineering and an MBA in IT Strategy, I bring together deep technical foundations and strategic thinking. My work is for engineers and digital tech professionals who want to better understand how software systems work, how teams scale, and how to grow into thoughtful, effective leaders.
Continue reading
Infrastructure as Code: The Secret Behind Scalable Cloud Systems
Understanding how engineers manage servers, databases, and cloud infrastructure using code instead of manual setup