How Software Systems Scale: From One Machine to Many
From a single server to intelligent auto scaling, a practical mental model for how modern software systems grow with demand.
Sandeep Varma

Scaling is one of those topics that sounds intimidating at first, especially if you are not coming from a traditional software engineering background. Words like scaling, load balancing, and auto scaling get thrown around a lot, often without context. The result is that systems feel abstract and hard to reason about.
In this post, I want to build an intuitive understanding of how software systems scale, why scaling is even needed in the first place, and what some of the common scaling mechanisms look like at a high level. The goal here is not to go deep into any one technique, but to create a mental model that makes future deep dives easier.
To do that, we will follow the journey of a very simple and relatable example and watch how it evolves over time.
Starting With a Personal Streaming App
To understand scaling, it helps to start small.
Imagine that I have recorded a bunch of videos for myself. They might be personal recordings, tutorials, or content I created just for fun. I want an easy way to upload these videos and watch them later, so I decide to build a small application for myself.
I upload the videos to my laptop and write a simple frontend application that lets me browse and play them. Behind the scenes, I also write a small backend application that knows how to fetch video files from storage. To make the experience better, I add a small database that keeps track of which videos I have watched and how far along I am, so I can resume playback later just like you would on Netflix or Prime Video.
At this point, everything lives on my laptop. The frontend, the backend logic, the database, and the video files are all on the same machine. It is simple, cheap, and it works perfectly for one user, me.
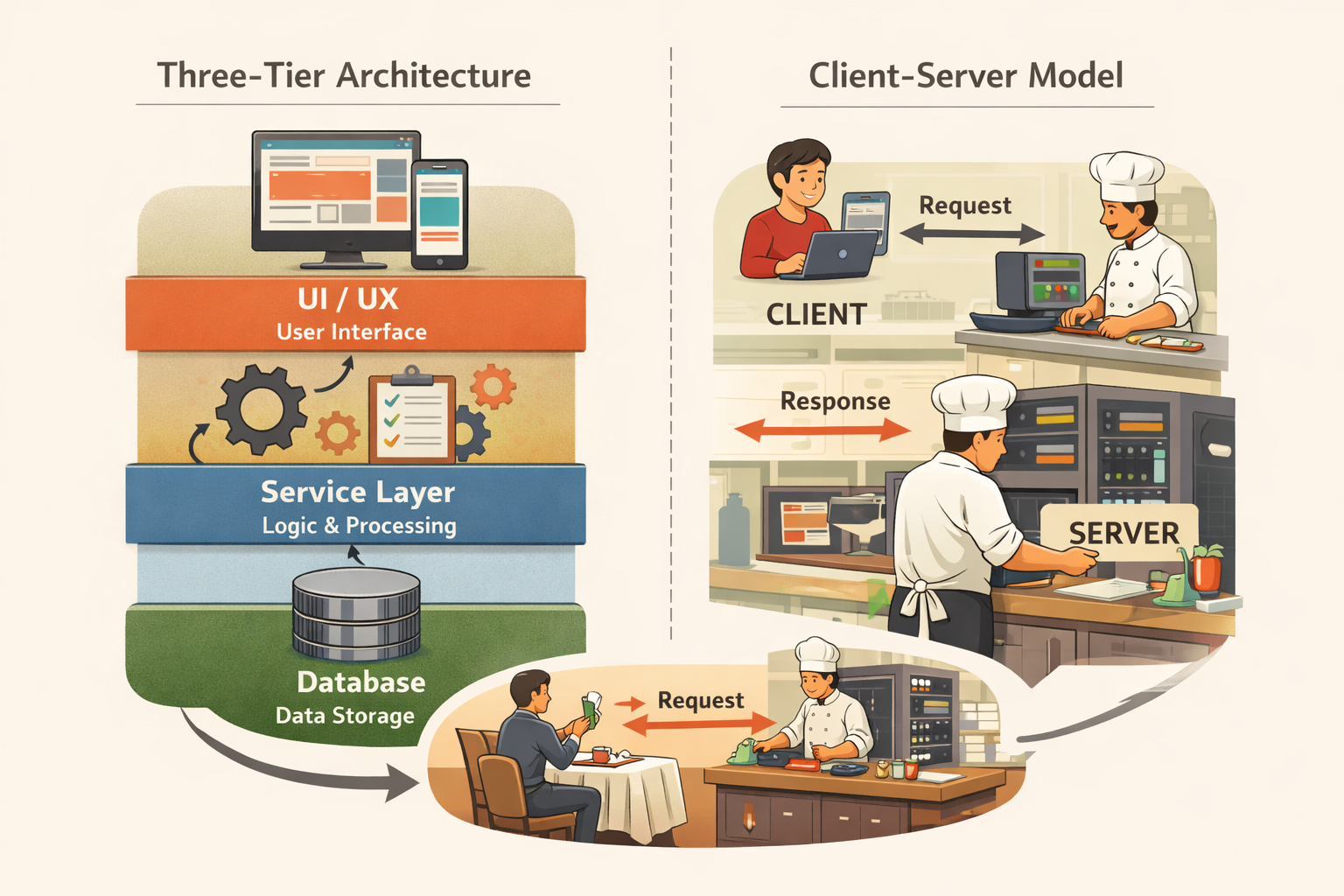
If you are already familiar with ideas like frontend, backend, APIs, and three tier architecture, you will recognize this structure immediately. If not, this is a great place to pause and review those fundamentals detailed in Three-Tier Architecture and the Client-Server Model, because everything that follows builds on that mental model.
Moving From a Laptop to the Cloud
After using this setup for a while, I realize I want to access my videos from more than just my laptop. Maybe I want to watch them on my phone, my tablet, or while I am traveling. Running everything locally no longer makes sense.
To solve this, I rent a small machine from a cloud provider and move my entire application there. Just like my laptop, this machine has storage for videos, memory and CPU for processing, and enough capacity to run my frontend, backend, and database together.
To keep costs low, I start with the smallest machine I can get away with. Everything is still running on one server, just no longer under my desk. From a functional perspective, nothing has changed. The system still works exactly as before, but now it is accessible securely from anywhere.
This single machine setup is extremely common in the early stages of many products.
Sharing With Friends and Feeling the First Limits
After some time, I decide to share this application with a few friends. They like the content and start creating accounts. More videos get uploaded. More people start watching at the same time.
At first, everything is still fine. But gradually, I start noticing some issues. Videos take longer to load. The system feels sluggish when multiple people are using it. Storage space is running low, and the database feels slower as it grows.
This is the first moment where scaling becomes a real concern. The system is no longer serving a single user with predictable behavior. It is now serving multiple users with overlapping usage patterns.
Vertical Scaling: Making One Machine Bigger
The simplest response to this problem is to make the existing machine more powerful.
Instead of changing the architecture, I upgrade the server. I add more storage so I can hold more videos. I increase the memory so the database can keep more data in RAM. I add more CPU power so the backend can handle more requests at once.
This approach is called vertical scaling. You still have one machine, but you keep increasing its capacity.
Vertical scaling is simple to understand and easy to implement. There is no need to redesign the system or change how components talk to each other. For a while, this works very well.
But vertical scaling has two big limitations. First, machines are not infinitely powerful. There is always a ceiling to how much CPU, memory, and storage you can add. Second, costs tend to increase quickly. Larger machines are significantly more expensive, and the price often grows faster than the value you get.
Eventually, you hit a point where vertical scaling is no longer a good solution.
Separating the Layers Across Machines
Once the single machine becomes a bottleneck, the next natural step is to start separating concerns.
Instead of running everything on one server, I move the database to its own machine. This immediately frees up resources on the original server, allowing it to focus on serving users rather than handling heavy database workloads.
As the system continues to grow, I take another step and move the backend API layer to its own machine as well. Now the frontend, the API layer, and the database each run on separate servers.
At this point, the system still follows the same three tier architecture, but each tier has its own dedicated resources. This separation allows each layer to be managed and scaled independently.
However, growth does not stop here.
Hitting Limits Again and Thinking Horizontally
As more users join and paid memberships are introduced, even this setup starts to feel the strain. Each individual layer now has its own limits. The API server can only handle so many requests. The frontend server can only serve so many users at once. The database can only process so many queries.
This is where horizontal scaling comes into play.
Instead of making one API server bigger, I add more API servers. Instead of a single machine handling all requests, I now have multiple identical machines that can respond to API calls. If one server could handle a certain amount of traffic, five servers can handle roughly five times that amount.
This is horizontal scaling. You increase capacity by adding more machines instead of making a single machine larger.
Introducing Load Balancing
Once you have multiple machines doing the same job, you need a way to distribute incoming requests.
Users do not decide which API server to talk to. Instead, there is a component in front of the system that receives incoming traffic and routes each request to one of the available servers. This component is called a load balancer.
The load balancer’s job is simple. It spreads traffic across multiple machines so that no single server becomes overwhelmed. In doing so, it helps the system stay responsive and stable even as traffic increases.
Load balancing is a deep topic with many strategies and tradeoffs, but at a conceptual level, it is enough to think of it as traffic control for your system.
Auto Scaling: Scaling Without Guesswork
At this stage, you might wonder why not just run a large number of servers all the time. The answer is cost.
Traffic is rarely constant. Some days are busy. Others are quiet. Paying for a fixed number of machines means you are often paying for capacity you are not using.
Auto scaling solves this problem.
With auto scaling, the system monitors traffic and resource usage automatically. You might start with two API servers. As traffic increases and those servers cross a certain threshold, such as CPU usage or request latency, the system automatically starts a third server. If traffic continues to grow, more servers are added.
When traffic drops, the system does the opposite. Extra servers are shut down so you are not paying for unused capacity. Your cost becomes proportional to actual usage rather than peak assumptions.
Auto scaling allows systems to be both scalable and cost efficient without constant human intervention.
Bringing It All Together
By starting with a single machine and gradually evolving the system, we can see how scaling emerges as a response to real constraints rather than abstract theory.
Systems usually scale in stages. First by making one machine bigger. Then by separating responsibilities across machines. Then by adding more machines for the same role. And finally by automating the process so the system can respond to changing demand on its own.
You do not need to design for massive scale on day one. Most successful systems grow into their architecture over time, guided by real usage patterns and business needs.
Final Thoughts and What Comes Next
This post is intentionally conceptual. The goal is to help you build an intuition for how software systems scale and why certain architectural patterns exist.
In future posts, we can dive deeper into individual topics like load balancing strategies, database scaling, or how microservices fit into this picture. For now, having a clear mental model is far more valuable than memorizing specific tools or technologies. If you want to go deeper into the infrastructure layer that makes dynamic scaling possible in the cloud, Infrastructure as Code: The Secret Behind Scalable Cloud Systems explains how teams define and manage that infrastructure consistently at scale.
If you made it this far, I would love to hear from you. What parts of scaling were confusing before this? What would you like to explore more deeply next? Share your thoughts, questions, or real world experiences in the comments.
Did you find this useful?
Comments
Loading comments...
Please log in to post a comment.
About the author

I write about leadership and software engineering through the lens of someone who’s worked as a software engineer, product owner, and engineering manager. With a Bachelor’s in Computer Science Engineering and an MBA in IT Strategy, I bring together deep technical foundations and strategic thinking. My work is for engineers and digital tech professionals who want to better understand how software systems work, how teams scale, and how to grow into thoughtful, effective leaders.
Continue reading
Are You the Boss They Celebrate When You’re Away?
How to build a team that values your presence, not one that feels relief when you are out of office.
From Idea to Launch: How Software Actually Gets Built
Understanding the journey from business idea to production release through prototypes, sprints, and continuous iteration.